Provjeravanje izgovorljivosti riječi pomoću Zakona sonornosti (Sonority Sequencing Principle)
Jedno od osnovnih principa kroslingvističke fonotaktike jest Zakon sonornosti, poznat u engleskoj literaturi kao Sonority Sequencing Principle. On kaže da neki suglasnici imaju veću sonornost, to jest, sličniji su samoglasniku od drugih, i da ti suglasnici koji imaju veću sonornost imaju tendenciju ići prema sredini sloga. Mnogi jezici dopuštaju samoglasno 'l' (kao u hrvatskom bicikl), i neki jezici dopuštaju samoglasno 'n', ali vjerojatno nijedan jezik ne dopušta samoglasno 'p' ili samoglasno 't'. I zato će mnogi jezici dopustiti riječ plant, ali rijetko koji jezik dopustiti će riječ *lpant ili *platn. Cilj ovog rada je provjeriti koliko dobro algoritmi klasifikacije mogu razlikovati izgovorljive riječi od lažnih riječi samo na temelju sonornosti glasova u njima.
Odgovor servera:
{}
Kako to funkcionira
Različite skupine glasova imaju različitu sonornost, koja se može predstaviti određenim brojem. Što je taj broj veći, to je glas sličniji glasu /a/ (niskom otvorniku):
BEZVUCNI_PRASKAVAC = 1 ZVUCNI_PRASKAVAC = 2 BEZVUCNI_SLIVENIK = 3 ZVUCNI_SLIVENIK = 4 BEZVUCNI_TJESNJAC = 5 ZVUCNI_TJESNJAC = 6 NAZAL = 7 LATERAL = 8 ROTACIST = 9 VISOKI_OTVORNIK = 10 SREDNJI_OTVORNIK = 11 NISKI_OTVORNIK = 12
I zatim se za svako slovo abecede određuje kakvu vrstu glasa predstavlja:
sonornost_fonema = {
'a' : NISKI_OTVORNIK,
'b' : ZVUCNI_PRASKAVAC,
'c' : BEZVUCNI_SLIVENIK,
'č' : BEZVUCNI_SLIVENIK,
'ć' : BEZVUCNI_SLIVENIK,
'd' : ZVUCNI_PRASKAVAC,
'đ' : ZVUCNI_SLIVENIK,
'e' : SREDNJI_OTVORNIK,
'f' : BEZVUCNI_TJESNJAC,
'g' : ZVUCNI_PRASKAVAC,
'h' : BEZVUCNI_TJESNJAC,
'i' : VISOKI_OTVORNIK,
'j' : VISOKI_OTVORNIK, # Znam da tehnički nije.
'k' : BEZVUCNI_PRASKAVAC,
'l' : LATERAL,
'm' : NAZAL,
'n' : NAZAL,
'o' : SREDNJI_OTVORNIK,
'p' : BEZVUCNI_PRASKAVAC,
'q' : BEZVUCNI_PRASKAVAC,
'r' : ROTACIST,
's' : BEZVUCNI_TJESNJAC,
'š' : BEZVUCNI_TJESNJAC,
't' : BEZVUCNI_PRASKAVAC,
'u' : VISOKI_OTVORNIK,
'v' : ZVUCNI_TJESNJAC,
'w' : VISOKI_OTVORNIK, # Opet, znam da tehnički nije.
'x' : BEZVUCNI_SLIVENIK, # Nisam siguran bi li bio.
'z' : ZVUCNI_TJESNJAC,
'ž' : ZVUCNI_TJESNJAC
}
I nakon toga se riječi pretvaraju u niz brojeva koji predstavljaju vrste glasova:
def pretvori_rijec_u_niz_sonornosti(rijec): niz_koji_vracamo = [] for i in range(0, maksimalna_duljina_rijeci): niz_koji_vracamo.append(0) if len(rijec) > maksimalna_duljina_rijeci: return niz_koji_vracamo for i in range(0, len(rijec)): if not(rijec.lower()[i] in sonornost_fonema): return niz_koji_vracamo niz_koji_vracamo[i]=sonornost_fonema[rijec.lower()[i]] return niz_koji_vracamo
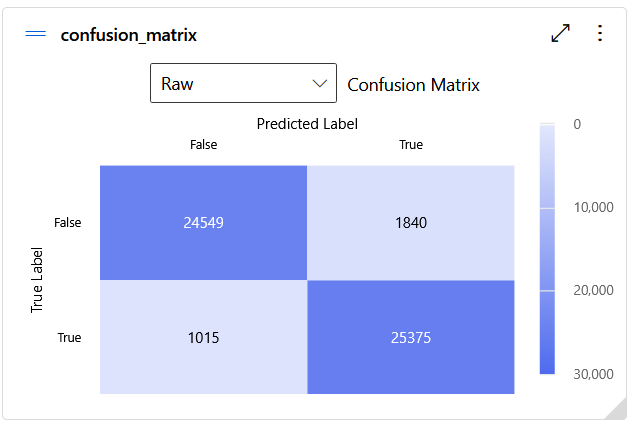
Stvarne riječi možemo preuzeti iz Aspella (spell-checkera otvorenog koda), dok izmišljene riječi (koje, naravno, ne moraju poštovati Zakon sonornosti, i najčešće ne poštuju) možemo jednostavno generirati. I njima možemo istrenirati neki algoritam klasifikacije, recimo, VotingEnsemble (koji kombinira razne algoritme klasifikacije i onda oni glasovaju određenom težinom koji će rezultat klasifikacije biti, a najveću težinu ima XGBoostClasifier s normalizacijom podataka koju pravi StandardScalerWrapper, koji imaju 20% težine, a blokirani algoritmi su TensorFlowLinearClassifier i TensorFlowDNN). On će nevjerojatno točno i precizno moći razlikovati stvarne riječi od nasumično generiranih samo na temelju sonornosti glasova:
Je li Zakon sonornosti jedino kroslingvističko fonotaktičko pravilo?
Naravno, Zakon sonornosti nije jedino kroslingvističko fonotaktičko pravilo. Većina jezika ne bi dopuštala etrursku riječ tisš ("u smjeru velike vode", jer t(h)i znači voda, -s- je sufiks za uvećanice, a -š je sufiks koji znači "u smjeru"). U većini bi se jezika dogodila disimilacija između s i š ili bi se umetnulo epentetsko t između njih, unatoč tomu što s i š imaju približno jednaku sonornost (pa riječ tisš ne krši Zakon sonornosti). Ali Zakon sonornosti najvažnije je takvo pravilo.
Utjecaj Zakona sonornosti na p-vrijednosti uzoraka u toponimima
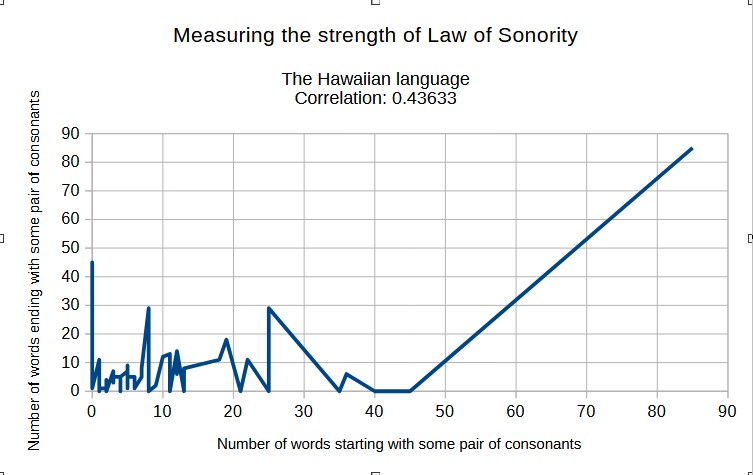
Zakon sonornosti ima velik utjecaj na p-vrijednosti uzoraka u toponimima (nazivima mjesta). To je zato što Zakon sonornosti implicira da što je neki suglasnički skup vjerojatniji na početku riječi, to je manje vjerojatan na kraju riječi. To pak implicira da u jezicima koji dopuštaju mnoge suglasničke skupove na početcima i na krajevima riječi, kao što je hrvatski jezik, parovi suglasnika na početku i na kraju riječi imaju približno za 1 bit manju kolizijsku entropiju nego što imaju parovi suglasnika u sredini riječi.
Ovako izgleda korelacija između parova suglasnika na početku i na kraju riječi na havajskom jeziku (koji ne dopušta nikakve suglasničke skupove - nakon svakog suglasnika slijedi samoglasnik):
A ovako ona izgleda za hrvatski jezik:
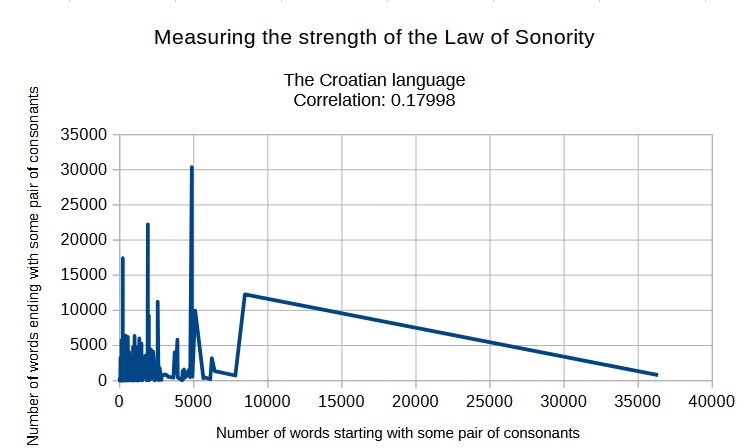
Vidimo da je u jezicima s lenijentnom fonotaktikom, kao što je hrvatski jezik, ta korelacija veoma niska.
I zato ako se pokuša p-vrijednost tog k-r uzorka u hrvatskim nazivima rijeka (Krka, Korana, Krapina, Krbavica, Kravarščica, i dvije rijeke po imenu Karašica) procijeniti metodama koje se uče na kolegiju Teorija informacija (pomoću kolizijske entropije i rođendanskog paradoksa), dobit ćemo da je p-vrijednost negdje između 1/300 i 1/17, dok, ako napravimo računalnu simulaciju koja uzima u obzir Zakon sonornosti, dobit ćemo da je p-vrijednost negdje oko 85%. Ogromna razlika, zar ne?
Ako vjerujemo da je model baziran na osnovama teorije informacije prikladan za toponime, čini nam se da je veoma vjerojatno da je na ilirskom jeziku postojao glagol *karr~kurr sa značenjem teći, i da ime rijeke Karašica dolazi od ilirskog imena *Kurr-urr-issia (teći - voda - sufiks). Da je *Kurr-urr-issia posuđeno izravno iz ilirskog u praslavenski kao *Kъrъrьsьja, što je nakon Havlikovog zakona dalo *Karrasja, što je nakon jotacije i nestanka geminata prešlo u *Karaša, na što su Hrvati dodali svoj sufiks -ica. A, ipak, ako uzmemo u obzir Zakon sonornosti, ta nam se etimologija ne čini baš vjerojatnom.
Trenutno pokušavam objaviti članak o tome u nekom časopisu.